Открытая 9B-модель Lift для извлечения структурированных данных из документов по JSON-схеме
6голосов
от Марк СемёновКомпания Datalab открыла исходный код Lift — 9B-модели для извлечения структурированных данных из документов. Система принимает на вход PDF-файлы или изображения вместе с JSON-схемой и возвращает объект, при этом механизм schema-constrained декодирования гарантирует строгое соответствие заданному формату. Модель способна обрабатывать многостраничные документы за один проход, корректно извлекая значения, перенесенные между страницами.
На внутреннем бенчмарке разработчиков точность извлечения отдельных полей у Lift составила 90.2%, что сопоставимо с показателями коммерческой Gemini Flash 3.5 (91.3%) и превосходит специализированные открытые решения вроде NuExtract3 (81.5%) или Qwen3.5-9B (76.3%). При этом медианное время обработки одного документа составляет 9.5 секунды. Оценка проводилась с учетом сложных сценариев, включающих пересекающиеся данные, мультисурсную агрегацию и поля, которые намеренно должны оставаться пустыми.
Инструментарий проекта включает интерфейс командной строки для пакетной обработки директорий и локальное приложение Schema Studio для визуальной отладки структур. Установка базовой версии выполняется командой pip install lift-pdf, после чего поддерживаются два режима инференса: локальный через библиотеку HuggingFace и клиент-серверный с использованием vLLM.
Поделиться:
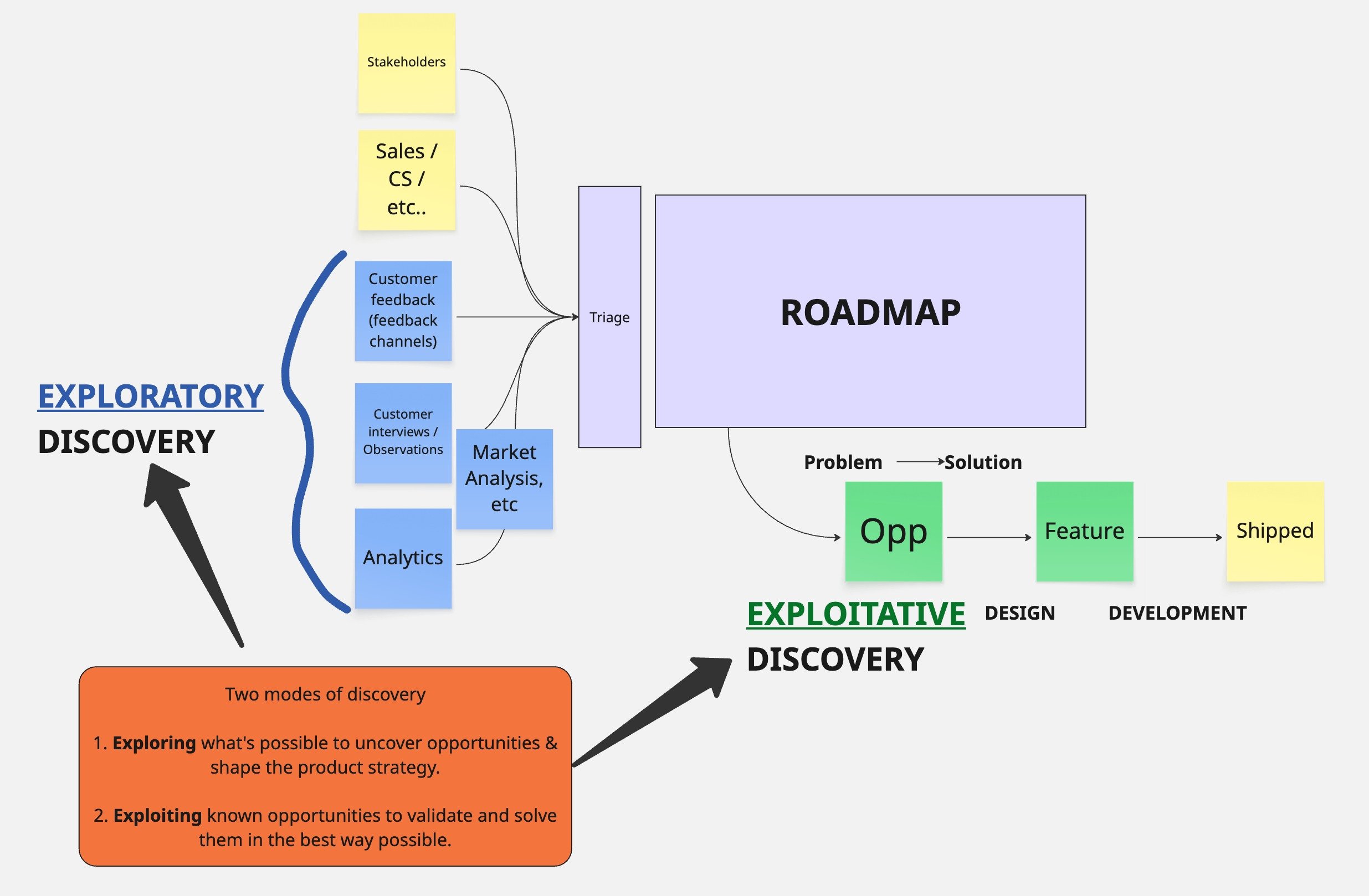
Два режима Product Discovery: почему метрики убивают поиск новых продуктов и как балансировать Explore и Exploit
Обновление Журналуса: двухколоночная лента и навигация по базе из 40 000 дизайн-материалов
Журналус выкатил редизайн ленты и 512-й выпуск: от Gaussian Splatting до открытой замены Claude Design
Вышел Журналус №512: открытая замена Claude Design, основы Gaussian Splatting и старт дизайна в текстовом редакторе