Очистка веб-страниц для LLM: как работает конвертер MD This Page
7голосов
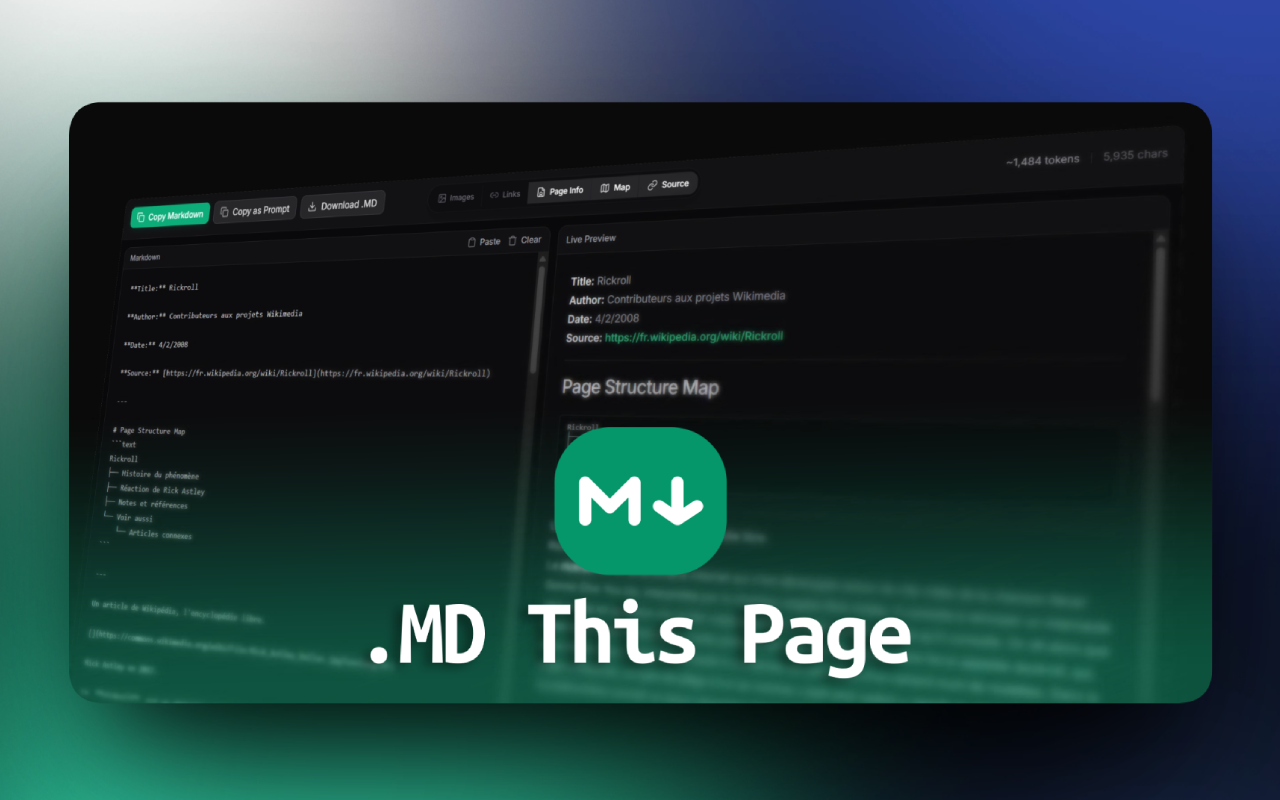
от tokenlimitПринято считать, что современные языковые модели легко переваривают любые ссылки и сырые веб-страницы. На деле парсинг HTML забивает контекстное окно мусором вроде навигационных панелей, скрытых скриптов и рекламных блоков. Модель тратит токены на разбор глубоко вложенного DOM, вместо того чтобы анализировать смысл текста. Проблему пытаются решать утилитами вроде MD This Page — браузерного расширения, которое превращает сайт в чистый Markdown, готовый для передачи нейросети.
Под капотом проект использует парсер Readability от Mozilla и конвертер Turndown. Алгоритм пытается изолировать основной контент, отсекая интерфейс и баннеры. В расширении предусмотрен предпросмотр результата, где можно отфильтровать изображения, ссылки и метаданные перед копированием в буфер. Структурированный Markdown действительно эффективнее для LLM: он сохраняет иерархию заголовков и списков, при этом весит в разы меньше исходного кода.
Правда, всегда ли автоматика спасает от хаоса современной веб-разработки? Эвристика Readability хорошо справляется с классическими статьями, но неизбежно пасует перед сложными дашбордами или динамическими SPA-приложениями. К тому же, инструмент написан на тяжелой связке React и фреймворка Plasmo, что кажется откровенно избыточным для задачи парсинга текста. Но для рутинного сбора данных под локальные RAG-системы такой подход пока остается самым рабочим компромиссом между скоростью и качеством.
Поделиться:
Поддержка LoRA-адаптеров в 3D-генераторе TRELLIS.2 от fal.ai
Кастомные LoRA для 3D-генерации: разбор тренера TRELLIS.2 от fal.ai