Результаты CursorBench 3.1: доминирование Fable 5 и эффективность Composer 2.5
8голосов
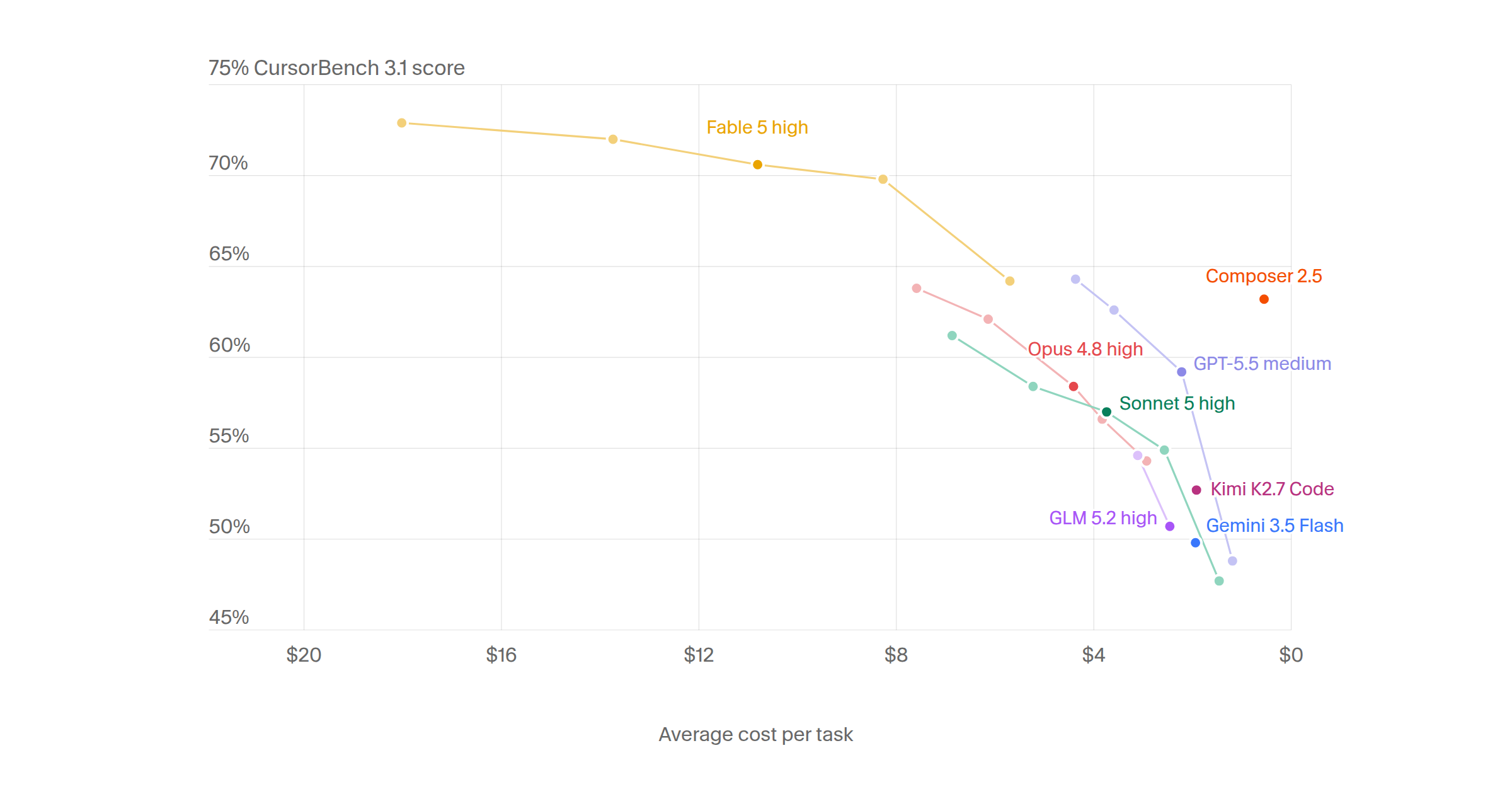
от inferenceonlyКоманда Cursor опубликовала результаты CursorBench 3.1. Это бенчмарк для ИИ-агентов на базе реальных многофайловых задач разработчиков. Лидером рейтинга стало семейство моделей Fable 5. Даже на настройках Medium (69.8%) модель обходит максимальные пресеты конкурентов. Ближайший преследователь Opus 4.7 Max выдает лишь 64.8%.
За высокое качество кода от Fable приходится платить. Решение одной задачи обходится от 8 до 18 долларов. С точки зрения стоимости выделяются два других решения. GPT-5.5 Extra High показывает 64.3% успеха при цене $4.37 за таск. Собственный движок Composer 2.5 решает 63.2% задач всего за $0.55.
В новой версии тестов добавили глубокий анализ кодовой базы и поиск багов. Азиатские модели GLM и Kimi пока отстают, набирая в среднем 50-54%. Для сложного рефакторинга сейчас логично выбирать именно Fable 5. Для повседневной рутины Composer 2.5 дает лучший баланс цены и качества.
Поделиться:
Интерактивная карта швейцарского маршрута Дж.Р.Р. Толкина как референс для миростроения
Слухи об ИИ-смартфоне от SpaceX: почему отрицание Маска выглядит как подтверждение тренда на новые физические интерфейсы