Рост автоматизации фриланс-задач в бенчмарке RLI: результаты Fable 5, Opus 4.8 и GPT-5.5
3голоса
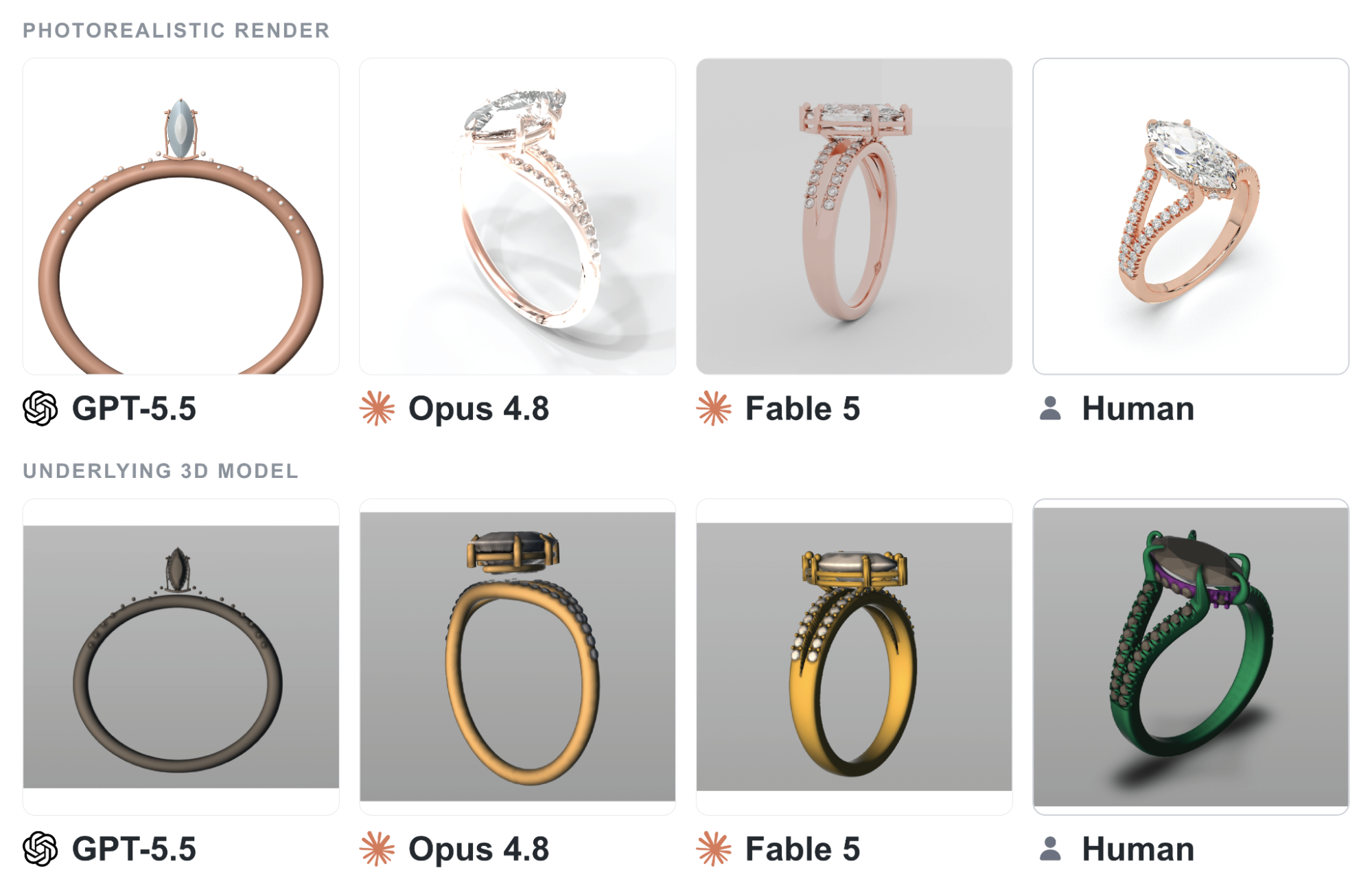
от sparsemodelОрганизация Center for AI Safety обновила результаты Remote Labor Index — бенчмарка, измеряющего способность ИИ-агентов выполнять реальные коммерческие заказы на уровне, который устроил бы платящего клиента. Для тестирования используются сотни закрытых проектов реальных фрилансеров с платформы UpWork. Новые данные показывают, что модель Fable 5 достигла уровня полной автоматизации в 16.1%, Opus 4.8 показал 8.3%, а GPT-5.5 остановился на 6.3%. Менее чем за восемь месяцев максимальный показатель на рынке вырос в четыре раза с изначальных 4.17%, что фиксирует быстрое развитие агентов в сложных дисциплинах вроде архитектуры, 3D-моделирования, видеомонтажа и анализа данных.
Для оценки модели помещаются в стандартные для индустрии среды разработки вроде Claude Code или Codex CLI, к которым добавляются инструменты управления компьютером. Агенты функционируют внутри виртуальной машины на Linux, где развернуто более 30 профессиональных программ, включая Blender и FreeCAD. Подобная архитектура позволяет системам напрямую взаимодействовать с графическими интерфейсами, анализировать исходные файлы заказчика и формировать готовые материалы, действуя по алгоритмам живого специалиста.
При этом верификация результатов всё ещё требует участия человека-эксперта, так как попытка исследователей внедрить автоматизированного LLM-судью привела к завышению показателей новых моделей в 2.5–3 раза. Проверка выполненного заказа сама по себе является сложной агентной задачей, требующей запуска файлов в профильном софте и детального анализа структуры проекта. В одной из задач по дизайну модель GPT-5.5 сгенерировала итоговую визуализацию с помощью сторонней нейросети, но не построила заявленную 3D-модель, что алгоритмический судья, не умеющий уверенно управлять интерфейсом программы для проверки скрытой геометрии, выявить не смог.
Поделиться:
Брутальная айдентика японского чайного дома Lambert от студии SODAA
Без пассивной агрессии и корпоративного пафоса: как составить адекватное прощальное письмо при увольнении