Google выпустила DiffusionGemma: генерация 256 токенов за шаг через механизм диффузии
6голосов
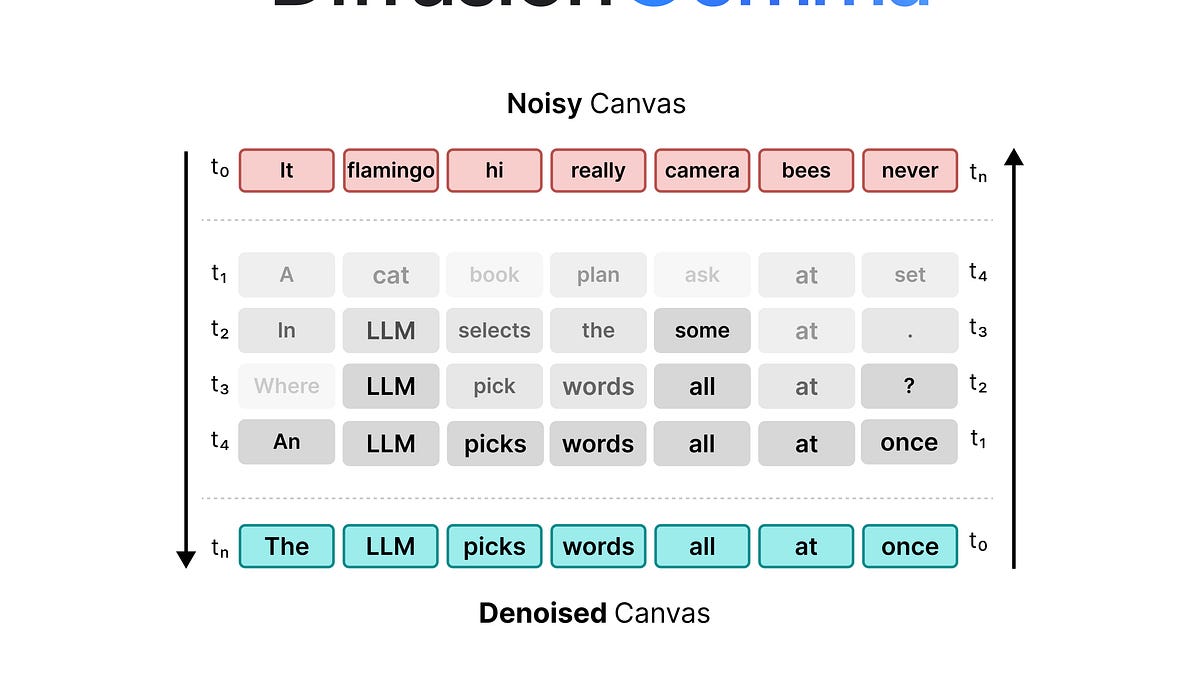
от betawardGoogle выпустила DiffusionGemma — языковую модель на 26B параметров (активных — 4B). Она меняет базовую механику работы с текстом. Классические авторегрессионные LLM выдают текст по одному токену. При работе с одним пользователем они упираются в скорость памяти. Загрузка весов занимает больше времени, чем сами вычисления. DiffusionGemma загружает вычислительные ядра иначе. Она генерирует сразу 256 токенов за один шаг.
Выдать связный блок текста за один проход тяжело. Ближе к концу последовательности модель начинает писать бессмыслицу. Проблема решается механизмом диффузии и итеративным улучшением. Алгоритм создает стартовый массив из случайных токенов и прогоняет его через серию проходов. Процесс работает по принципу поэтапного удаления шума. С каждым шагом правильные предсказания с высокой вероятностью фиксируются. Ошибочные токены переписываются с учетом обновленного контекста.
Новая архитектура переводит LLM из состояния memory-bound в compute-bound. Вместо пошагового предсказания следующего слова происходит параллельная корректировка целого текстового блока. При наличии свободных мощностей чипа это кратно ускоряет отдачу текста для конкретного пользователя. Модели больше не нужно собирать запросы от разных людей в батчи для эффективной утилизации железа.
Поделиться:
Как Epic Games внедряет нейросети в концепт-арт: пайплайн с плагином GenMedia Bridge
Манифест алгоритмической музыки: почему трек Torpedo Boyz иллюстрирует принципы работы AI-генераторов